Publish and preserve
Last updated on 2026-04-14 | Edit this page
Overview
Questions
- What is data archiving?
- What are data repositories?
- What is a DOI, and why is it important?
Objectives
- Understand the role of trusted repositories in long-term preservation.
- Learn why repositories improve discovery and citation.
- Understand how DOI supports persistence and citation.
FAIR principles used in data archiving
Findable:
- FM-F1A Identifier Uniqueness: https://doi.org/10.25504/FAIRsharing.r49beq
- FM-F3 Resource Identifier in Metadata: https://doi.org/10.25504/FAIRsharing.o8TYnW
Accessible:
- FM-A2 Metadata Longevity: https://doi.org/10.25504/FAIRsharing.A2W4nz
What is data archiving?
Data archiving is the long-term preservation of research data and related digital objects.
Funders and journals increasingly expect enough of the data and methods to be preserved so that results can be inspected, understood, and, where possible, replicated.
What are data repositories?
Data repositories are storage locations for digital objects such as datasets, code, supplementary files, and metadata.
Repositories make research outputs easier to find and can also provide:
- preservation
- backup
- citation infrastructure
- versioning
- controlled access options
Examples:
| Repository | About |
|---|---|
| DataverseNL | Community repository supporting Dutch universities and research centers |
| 4TU Data | Repository originally developed by Dutch technical universities |
| PANGAEA | Domain repository for Earth and environmental sciences |
| Figshare | General-purpose repository for many digital object types |
General repository recommendations
- Zenodo: https://zenodo.org/
- SURF Repository: https://repository.surfsara.nl/
- DataverseNL: https://dataverse.nl/
Aim for a community repository when it exists. If not, a trusted general repository is usually better than leaving data only on a local drive or project website.
Typical strengths of general-purpose repositories include:
- persistent identifiers
- rapid publication
- versioning
- backup and preservation
- usage statistics
- open or restricted access modes
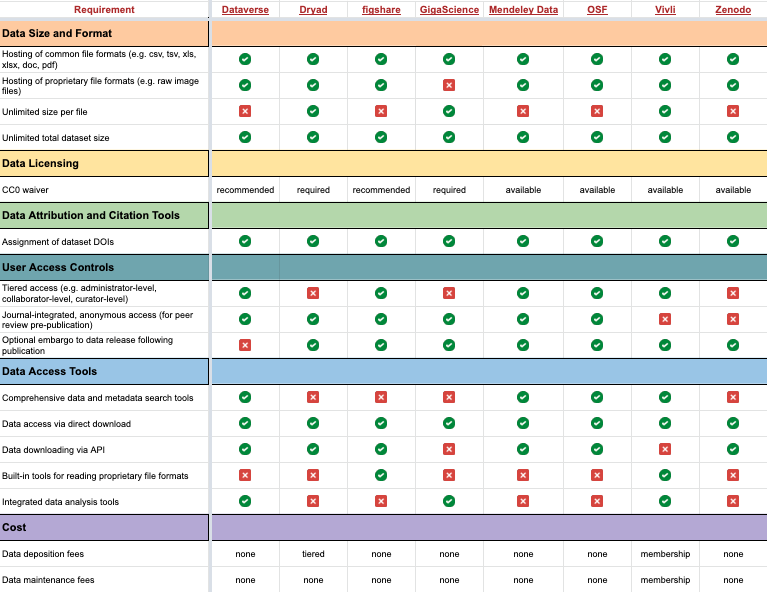
Additional registries that help identify suitable repositories:
- re3data: https://www.re3data.org/
- PLOS recommended repositories: https://journals.plos.org/plosone/s/recommended-repositories
- NIH repositories guidance: https://sharing.nih.gov/data-management-and-sharing-policy/sharing-scientific-data/repositories-for-sharing-scientific-data
- OpenDOAR: https://v2.sherpa.ac.uk/opendoar/
For context on the original Dataverse model, see Harvard Dataverse:
- https://dataverse.harvard.edu/dataverse/harvard
- Introductory video: https://www.youtube.com/watch?v=MPQ0Tpgaxt0
Exercise
Visit https://dataverse.org/ and inspect the current installation map and the DataverseNL portal.
Answer:
- How many Dataverse installations are listed now?
- How many are in the Netherlands?
- Roughly how many datasets are visible in DataverseNL at the time of your visit?
These counts change over time, so record the values you observe at the moment you complete the exercise rather than relying on historical numbers from older lesson versions.
What is a DOI, and why is it important?
DOI is a persistent identifier commonly used for articles, datasets, reports, and other scholarly outputs.
Two major DOI registration services in research are:
- Crossref: https://www.crossref.org/
- DataCite: https://datacite.org/
A DOI has three conceptual parts:
- the resolver service
- the registrant prefix
- the locally assigned suffix
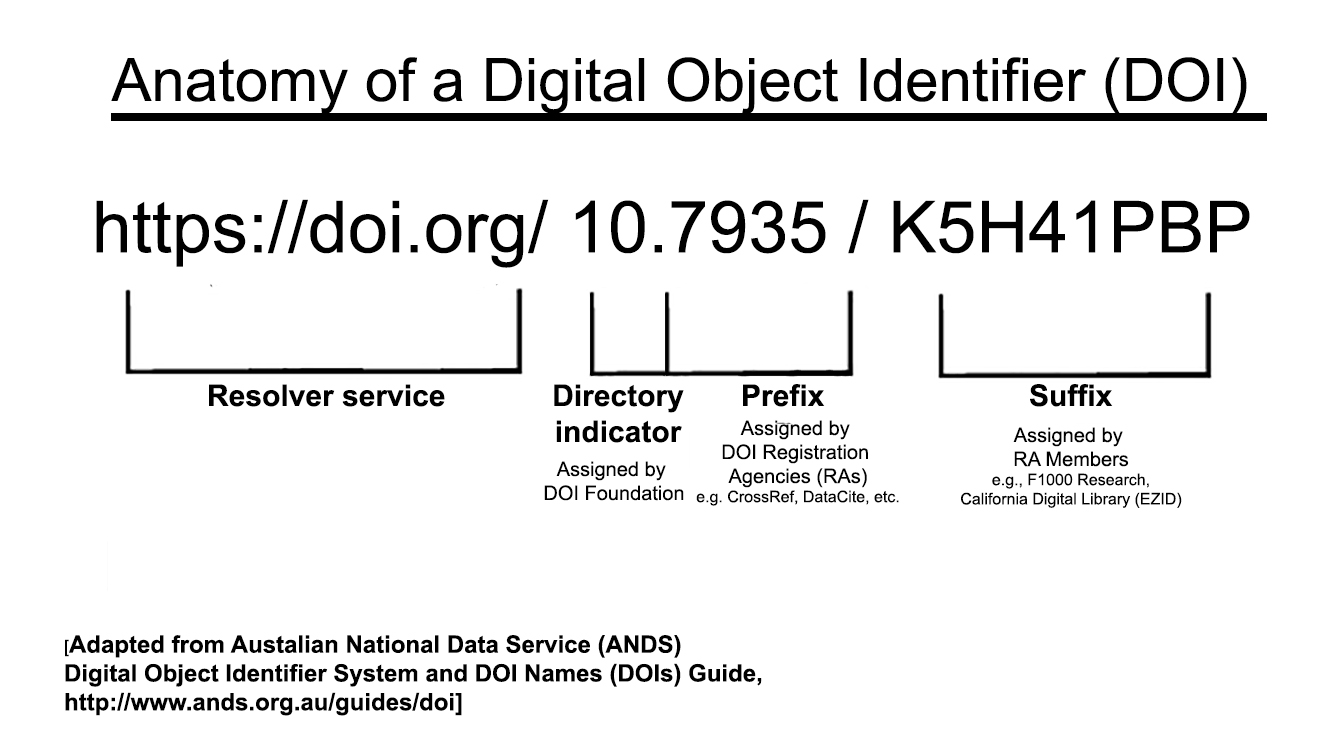
DOIs make resources easier to cite and track, and they continue resolving even when storage details change.
Exercise
Upload a test dataset to the DataverseNL demo or another training repository:
- Download the mock dataset: MOCK DATA
- Deposit it in a suitable demo or sandbox repository
- Record the DOI or persistent identifier you receive
There is no single correct answer. The point is to experience how a repository assigns persistent identifiers and what metadata are required before publication.
Scenario
You conducted personal interviews for an ethnographic migration study. The raw transcripts cannot be openly shared, even under restricted access.
How should archiving be handled in this case? What metadata, derived outputs, or access statements should still be preserved and published?
- Repositories improve preservation, discovery, and citation.
- Prefer a trusted community repository when one fits your discipline.
- General repositories such as Zenodo still provide a strong baseline for FAIR publication.
- DOI is a key persistent identifier for datasets and publications.